JavaのDBアクセスライブラリ jOOQ の紹介
先日、とある会社の方に、DBアクセスするにはjOOQ(ジョーク 【訂正】ジュークと読むらしく公式に発音記号が定義されている)というライブラリが良いと教えて頂いた。
名前はなんとなく見たことがある気がするものの、実際のところどういった物なのか知らなかったので、個人的に気になる点を調べてみた。
実際に使い倒したわけではなく、使ってみたら不満とか解決策とか見つかるかもしれないので、その点はご容赦を。
対象読者
jOOQが何か簡単に言うと?
ドキュメントを探しても、ズバリ一言で「jOOQは〇〇である」という記載は見つからない。ドキュメント 3.3. Different use cases for jOOQに
jOOQ has originally been created as a library for complete abstraction of JDBC and all database interaction.
と書かれており、DBアクセスを全てカバーしたいことは分かるが、どういう特徴があるかは一言では書かれていない。
一方で、他のツールとの対比や利用のバリエーションは色々書かれている。
例えば、jOOQのGitHubリポジトリのREADME.mdを私なりに要約すると、JPAやLINQのような仕組みはSQLを隠そうとするあまり高度なクエリ発行が難しいと言っている。
また、ドキュメント 3.3. Different use cases for jOOQから抜粋すると、
- 型安全にSQLを組み立てられる。
- クエリ実行に便利な機能を用意している。ロギングなどの開発補助も入っている。
- HibernateとjOOQを組み合わせて使うのもあり。
- jOOQにはソースコードジェネレーターがあるけど、それは使わなくてもよい。
などあれこれ書かれている。
これらを踏まえると、「Javaの型の恩恵を受けながらSQLを直接記述したいときに使うライブラリ」と言えそうだ。
競合は?
jOOQ公式ではJPA(Hibernate)を非常に意識している。ただ実際にはSQLを自在に実行できるライブラリとして、MyBatisやDoma 2などが競合にあたるように思う。
MyBatisもDoma 2もいくつか使い方があるが、主には、
- MyBatis … SQLをファイルに記述する。条件分岐などはXMLタグで表現する。
- Doma 2 … SQLをファイルに記述する。SQLコメントをDoma 2が解析して条件分岐などを制御する。
- jOOQ … JavaのソースコードでSQLを記述する。
という使い方になると思われる。型安全にするためにJavaの中でSQLを組み立てるのにこだわっている点で、他のライブラリとは方向性が異なる。
気になったこと一覧
感想
気になる事を一覧で出してみた結果、ほとんどが「○」だったので実用性は十分だと思う。
悩む点:ベストマッチなシチュエーション
SQLライクな記述をしたいという需要に応えるライブラリなので、複雑なSQL、特にSELECT文を発行するときに真価を発揮するはずだと思ったので少し考えてみた。
複雑なSQLには、
の2パターンがあると思う。
1.については、頭の中でSQLを考えるのであれば、Javaではなく別ファイルにSQLを書く形式の方が素直なのではと思う。 一方で2.については、Javaの処理で書くよりも、MyBatisでXMLで宣言的に書いたりする方がスッキリすると個人的には感じていて、これもjOOQがベストとは言いかねる感じがある。
ではどんな時に真価を発揮するのか?
これは想像になってしまうが、そこまで複雑ではないけど、色々なパターンのSQLを書かなくてはいけないときなのかなと今のところ思っている。
あと、自分は普段Javaを書いているが、Kotlinなどから呼び出すときには印象が変わるかもしれない。
他より分かりやすく優れる点
Spring Boot連携の扱いは特徴である。
StarterパッケージがSpring Bootから公式に出されているのは頼もしいポイントで、MyBatisやDoma2よりもSpringのバージョンアップで使えなくなるリスクが低いと考えて良いと思う。 (Spring Bootが出している情報全般に言えることだが)ドキュメントが少ないのでソースコードを読む必要があるのが玉に瑕だが、それでも十分な利点だと思う。
あとは、上には表現されていない使い方の特徴として、基本的にソースコードはDB定義から自動生成するのが基本のようになっている点がある。 逆に、自動生成しないと文字列で記述する部分が多くて、型安全の恩恵を受けることが出来なくなってしまうとも言える。
自動生成にもオプションが多数あり、最初にどういうコードを自動生成させるかが大事になってくる点が他との違いである。
最後に
この手のライブラリを使うときに何を重視するかは人それぞれだと思う。上記を見て気になったことがあれば試して見て欲しい。
自分ももう少し触ってみて、気づいた事があれば更新を掛けていきたい。
Azure Developer Associate 向いている人/勉強方法
Microsoft Azureの開発者向け資格の Azure Developer Associate を受験して、なんとか合格しました (/・ω・)/
その感想として、これから受ける人向けの情報をいくつか書こうと思います。
この記事を書いた動機
この資格の情報が少ないです。特に日本語情報がなかなか見当たりません。そういう点も含めて、AWS等の同様の資格よりも癖が強い資格だと感じました。
そんな中で他の人の個人ブログの記事が役に立ったので、忘れる前に自分も記録を残しておこうと思いました。
どんな人向けの資格か?
向いている人
次の項目をすべて満たしている人です
- 英語の資料だけでも勉強できる ← けっこう大事
- C#で、ASP.NETおよびASP.NET Coreを使って実装を行っている。
- Azureの主要なPaaSを利用している、もしくは利用したいと思っている。
- その中でも「全部AKSで…」などという形ではなく、「FunctionsとLogicAppsとServiceBusと…」というように使い分けている(分けたいと思っている)
再考した方がいい人
次のいずれかに当てはまる人には勧めにくいです。
- 日本語だけで完結させたい
- JavaやNode.jsやPHPでAzure上で動くプログラムを組んでいる
- ベンダーロックインされないように、他のクラウドと共通点の多いサービスを主として利用している
- 仮想マシン、Kubernetes etc.
参考となるテキストも模擬試験(公式、非公式それぞれ)も、いずれも英語が基本です。記事執筆時点では、まず試験範囲を知るためにすら英語のPDFを開くしかありません。
唯一の日本語で使える資料としてMicrosoft Learnにこの資格向けの独学用資料があるものの、試験範囲と必ずしも一致していないですし、これだけだと落ちる可能性が高いので注意が必要です。
また、試験本番も変な翻訳が交じった日本語での出題になるので、何割かの問題は元の英文を確認するという作業が必要になりました。
ドキュメントと違う訳語が当たっているのは困りますね。
SDKの使い方レベルの話が出てきたりもしますが、Microsoftのサービス,資格なのでC#が基本となります。それ以外の言語を使っている人は、「いや、C#でのクラス名とか文法的な注意点とか知らないし…」という気持ちになると思います。
Pythonという選択肢もあるみたいですが、受験方法によってはC#限定だったりするのでやっぱり基本はC#です。JavaとNode.jsとPHPは蚊帳の外です。
あとこれは考えてみれば当然ですが、Microsoftとしては自社独自サービスを使うと他より楽になるよと主張したいわけです。
例えばAzureにはKubernetesやPostgreSQLやMongoDBをPaaS化したサービスがそれぞれありますが、そういうのは試験範囲に入っていないか、入っていても割合がかなり少なくなっています。App Service(Functions, Web Apps)やApplication Insightsなど独自性が高いものが主な対象でした。
どんな勉強をするか?
情報を集めながら勉強をしたので実際にはこの順ではありませんでしたが、 今から改めて勉強するならこの順が良いかなと思います。
1. 試験範囲を確認
まず、公式情報から最新の試験範囲を確認します。
2. 主要サービスを使ってみる
次に、Microsoft Learnの中のDeveloper Associate向けとなっているラーニングパスの中で、「このサービス使ったことないぞ」というのがあれば試します。試験対策としてはこれだけでは不十分ですが、Azureの体験には良い資料だと思います。
ただし、各サービスのドキュメントよりも更新が古いので、誤訳が残っていたり、現在と設定できる項目が違っていたりということがあります。
それから変な日本語があったら英語版を見てください。「認定資格」→「certificate = (SSL/TLSの)証明書」のことだったり。
3. Udemyで演習テストを受ける
Udemyに説明講座や演習テストがあります。
あ、全部英語です。英語だったらたくさん資料があります。私は1200円セールのときにいくつか買いました。
講座を英語で聞くのはなかなか厳しいし時間も吸われてしまいますが、演習テストだったらなんとかなります。 AZ-204 Microsoft Azure Developer Practice Tests とか AZ-204 Developing Solutions for MS Azure Practice Tests とかやりました。
上記2つの演習テストをしっかりやったら、問題の傾向や難易度、よく聞かれる内容も大体想像が出来るかと思います。
(なお、1つ目の方は少し簡単です。)
4. 苦手分野の勉強をする
演習テストを受けると苦手分野がなんとなく分かるので、MS LearnかUdemyの講座かで勉強します。
あまり細かくやるよりは、演習テストで合格点が取れるようになればまぁ十分なのかなと思います。
5. 受ける
他の試験より勉強しにくいので、合格点とれるかなと思ったら思い切って受けてしまうのが良いと思います。
演習テストを受けると分かりますが、「そんなの覚えている必要ないでしょ、必要なら調べるよ」って問題も正直出てきます。(例えば、Storageのトータルの最大容量を心配するサービスとか作る機会多分こないと思うんです。)
受験料が無駄になるのは避けたいですが、自分がAzureを使うために必要な知識よりも多くを覚える時間はもったいないです。
上の方でも書きましたが問題文の日本語がおかしくて、Azure上でやドキュメントでの表記と違ったりもするので英語表示を頻繁に確認することになります。(英語表示の機能がなかったら落ちてたと思います。)
まとめ
英語ができて、C#使っていて、PaaSを積極的に使っていきたい人向けの資格です。
特に最初の英語ができることが、勉強を始めるまで気づきにくいポイントです。他のIT系の資格(Oracle,AWS,LinuC等)も英語が出来た方がいいですが、この資格はその比ではなく英語できないと辛いです。 本来の勉強すべき対象ではないと思うので、MSさんによる今後の改善を期待しましょう。
OSSにプルリクが取り込まれた
先日、OSSに自分の書いたPull Requestが取り込まれるという実績解除(?)をしました。
別にOSS活動が偉いわけではないですが、凡人にはそれほど多い経験ではないですし今後の人生の励みにもなるかもしれないですよね。
ということで、8割が記念、2割が他の人の参考になるかもしれないという気持ちで、簡単に経緯を書いておきます。
ちなみに対象のリポジトリはAzure FunctionsのNode.js用ワーカーです。
きっかけ - 仕様の不明確さに対する不安
Microsoft Azureのサービスはいくつか使ったことがあります。
その中でも、Web AppsやFunctionsは、(DB部分を除けば)ほぼ無料でWebアプリケーションをデプロイできるので重宝しています。
ただFunctionsに関しては、なにやら機能が多いらしい割に、仕様が明確でないなと感じていました。
C#はクラスがはっきりしているし、MSが推してるからドキュメントも多数揃っているけど、Node.jsで使いたいなと。JavaScrptは型が曖昧だし、ドキュメントもC#より少なく見えるので隠れた仕様とかあるのではないかと思っていました。
そんなこんなで使い方を検索していた折、Azure Functions本体がGit Hubに公開されていることを知りました。そして、別リポジトリでNode.js呼び出し用のコードも公開されていることを知りました。それが上で書いたリポジトリです。
Azure Functions系のリポジトリを整理するリポジトリもありました。
バグ発見 - コードリーディング1時間
一番知りたいなと思っていたことは「自分の書いた関数はどうやって呼び出されているのか?」でした。そこで、自分の関数を呼び出しているらしい箇所を探しました。
比較的小さなリポジトリになっていたので、FunctionLoader.tsなるファイルもその中のgetEntryPoint()というめぼしい関数もすぐに見つかりました。
function getEntryPoint(f: any, entryPoint?: string): Function { if (isObject(f)) { var obj = f; if (entryPoint) { // the module exports multiple functions // and an explicit entry point was named f = f[entryPoint]; } else if (Object.keys(f).length === 1) { // a single named function was exported var name = Object.keys(f)[0]; f = f[name]; } else { // finally, see if there is an exported function named // 'run' or 'index' by convention f = f.run || f.index; } // ...略... return f; }
ほー、関数だけじゃなくて、複数プロパティを抱えたオブジェクトでも動くんだ、しかも丁寧なコメント付きだぞ。
ということで、3種類の指定方法を理解しました。
特に、最後のrun()やindex()が呼び出されるパターンは知らなかったぞ。試してみよう(※後からドキュメント読み返したら、たしかに書いてありました。)
そうやって書いてみたところ、なぜか想定どおりに動かずエラーになるパターンに遭遇。run()を定義しているのに、そこにたどり着かないぞ…
たまたまこの前日に別の有名OSSのバグっぽい挙動に遭遇したばかりだったので、Functionsのバグを引いた可能性をすぐに考えました。
測ってはないけど、リポジトリを見つけてからここまで1時間くらいだったと思います。
原因特定と対処検討
とりあえずGitHubのIssueを探し、該当事象に関するものが無いことを確認しました。
その後は、動作確認環境の準備です。幸い難しいことはなくて、README.mdに書いてあるとおりにしたらすんなりローカルで立ち上がりました。
そしてVisual Studio Codeを使って、エラーになるコードをデバッグ実行。
JavaScriptのObject.keys()は関数以外も拾ううえに、prototypeの関数を取得できないのが、自分の想定どおりに動いていない原因だと判明。
関数はprototypeに定義するのが一般的ですし、classを使う場合には勝手にそうなるので、考慮不足感がありますね。
原因がわかったところで、どう実装を変えるべきかを考えました。
ここでIssueに書いてMicrosoftの人に後は任せるという手もありましたが、原因が分かっているのと、英語で正確に伝えるよりコードで伝える方が簡単かもしれない説もあったので、自分でプルリクまで投げると決意しました。
一番気をつけたことは、互換性を崩さないこと。つまり、今までエラーになって起動できなかった例は起動できるようにするが、今まで動いていたプログラムは動きが変わらないこと。
Azure FunctionをNode.jsで使っている人が少ないとは思えませんし、少しでも破壊的変更が入れば、パッチの取り込みは慎重にならざるを得ないはずだからです。
それから、テストコードを書くことも気をつけました。
あまりテストコードの揃ったリポジトリではありませんでしたが、問題点/実現したいことが明確になり、動作保証にもなるのだから、こういう時にはテストは必須なのでしょう。
ここまで書いておいて難ですが、あまりJavaScript慣れてなくて、mock-requireって何者?? みたいになりながら書いたので勉強になりました。
IssueとPull Request、そして取り込みへ
Issueはソースコードを主体に記述しました。
- このコードでエラーになるよ
- 似てるけどこのコードはOKだよ
- EntryPointのこのコードが怪しいよ! (問題のソースコードを貼り付けて、該当行の横に矢印でコメント入れる)
で、その後に修正をPull Requestとして出しました。
英語マナーがわからないので、ドキドキでした。
Issue/Pull Requestを出した後には、日々「はやく取り込まれないかなー」「意図伝わってるかな…」とほぼ毎日リポジトリを覗きました。(※書いたIssueに何か動きがあったらメール通知が来るのは知ってましたが気分的にね。) シンプルな変更なのに1週間以上待つとちょっと不安になりますが、10日目で "This looks great - thank you! And thank you for adding tests :)!!" のコメントと共に取り込んでもらえました。ヤッタネ!
簡単に不具合(っぽい挙動)を見つけられた理由
JavaScript/TypeScriptに詳しいわけでもなければ、Azure Functionsの内部実装に詳しいわけでもない自分が、すぐに不具合に気づいた理由を考えます。
1. 規模の小さいリポジトリだった
Azure Functionsというサービスはなかなかに大きいですが、コア部分はC#で書かれていて、Node.js用の実装規模は小さいです。
リポジトリにファイルが多いと、目当ての機能を探すだけでも一苦労になってしまうので、当然かもしれませんが小さなリポジトリは初心者には優しいです。
2. コードを見ながら手を動かした
不具合に気づく前に、ソースコードを見ながら「ふ~ん」と手を動かしてみました。
この 「ソースコードを見ながら」「手を動かす」 というのがポイントなんだろうなと思います。
なぜそのコードが書かれたかという意図を考えながら深く読もうとする、そして実際の動きを確認して納得する/しないというのが、コード細部の理解につながるのかなと。
業務でプログラムを書く時には、多かれ少なかれドキュメントを書いてから手を付けることが多いと思います。ドキュメントを作らないスタイルの場合は、先にしっかり話し合いをして方針共有をするでしょう。
そういう状況とは手順が逆になるので、細部に気づくことができたのだろうと思います。
古より引き継がれし、ドキュメントが存在しないシステムのバグを見つけちゃったりするのは、こういう事なんですかね。(単に色々雑なだけかも。)
まとめとこれから
Azure Functionsという自分も使うことのあるOSSプロダクトに、Pull Requestを出して取り込まれました。
小さなパッチですが、不具合発見から取り込まれるまでの一連の手続きをちゃんと業務外で行ったのは初めてだったので、緊張したり喜んだりでした。
特にバグを探そうと意気込んでソースを読んだ訳ではありませんが、手を動かしていたら自然と発見しました。コードをちゃんと読むためには書くのも必要だと思いました。
Azureに貢献するべく云々というつもりは今の所ありませんが、一回経験したことで、不具合報告やPull Request提出に対する自分の中での心理的ハードルは下がったかなと思います。
OSSを使っていて何か怪しい動きに気づいたら、これからも何か行動できそうです。
余談ですが、途中にも書いた通りNode.jsはあまり使わないですし、フロント側もあまり知らないし、もうちょっとJavaScript強くなりたいですね。サーバー側をガリガリに書きたいときには、別言語を選択すると思いますが。
【統計 小ネタ】視聴率のずれ
今回はテレビの視聴率について。
年末になると視聴率のランキング形式で紹介していく番組があったりしますし、ネットで検索すれば細かい数字とともに紹介サイトがヒットします。(ex. https://tvkansou.info/rekidai2018/ )
ところで、視聴率の求め方や正確さって気にしたことはありますか?
視聴率の調査方法
日本テレビのウェブサイト 日テレ 広告ガイド に詳しい情報が出ています。
機械で測定する方式が2種類と、毎日どの時間帯にどの番組を見たかを手で記録してもらう方式があるそうです。
そして、各地域ごとにこちらに書かれた人数の参加世帯がいるとのこと。
最も大きな調査地区が、関東地区(※東京だけではない)の900世帯です。(表だと600になっている気がしますが…。)
札幌、宮城、福岡あたりもかなりの大都市を抱えていますが、それぞれ200世帯だけです。
視聴率の「誤差」
さきほどの日テレのサイト 視聴率には誤差がある!? | テレビCM検討編 | 日テレ 広告ガイド のほか、視聴率調査を行っているビデオリサーチ社のサイト 視聴率をご覧いただくときの注意事項 | 週間高世帯視聴率番組10 にも書かれていますが、 視聴率の測定には誤差が伴います。
上記サイトの表を見ると分かりますが、例えば関東地区限定の調査であれば、「視聴率10%」と測定されたとき、本当は8%以下や12%以上だった可能性が5%ほどあります。
地方のローカル番組であれば200世帯の調査のこともあるはずなので、そうすると「視聴率10%」は本当は5.8%以下や14.2%以上の可能性が5%ほどです。
ただし、上の計算はあくまで「1回あたりの視聴率が10%だった」ときの話です。1クールを13回の放送としてその平均視聴率をとれば誤差は13の平方根で割った値、すなわち約3.6分の1になります。2クールなら約5分の1です。
地方ローカル番組でも「2クールの平均視聴率10%」はほぼ9%から11%の間に収まります。
ラジオの聴取率と最先端の取り組み
テレビの視聴率の測定に、手作業での記録方式もあると書きました。ラジオは機械測定はされていなくて、測定習慣にやはり手作業で日記をつけてもらう方式で聴取率を測定しているそうです。 ラジオ個人聴取率調査 | コーポレートサイト || コーポレートサイト
今やネットラジオも広まりました。そんな中で、 首都圏ラジオ聴取データ × radikoデータ~推計によるラジオ聴取データの365日化へ~ | ニュース || コーポレートサイト 今の方式ではなく、radiko の聴取データと手作業での日記とを組み合わせた方式での聴取率の計算を準備しているとの発表がありました。
機械学習を使って、radikoユーザーだけが測定対象になることのバイアスを除去するということでしょうか。
感想
毎年視聴率ランキングを目にするわりに、視聴率がどのくらいの規模で計算されるかといったことは考えたことがありませんでした。関東地区でも900人というのは、かなり少ないという印象です。
「○○の瞬間、12.3%!!」みたいに扱われますが、0.1%刻みのランキングは真実を映し出してないかもしれませんね。
テレビと同様、ラジオにとっても聴取率が生命線でしょう。それが通年で測定されていないというのも意外でしたが、たしかに測定が大変だったというのも分かります。大事な指標が機械学習の予測値で良いのかという疑問もありますが、通年で測定できるようになるのは意義が大きそうです。
参考, 利用
- 書籍 「統計学入門」東京大学教養学部統計学教室 編(出版社サイト)
- 書籍 「人文・社会科学の統計学」東京大学教養学部統計学教室 編(出版社サイト)
- 日テレ 広告ガイド
- 調査エリアってどうなってるの? | テレビCM検討編 | 日テレ 広告ガイド
- 視聴率をご覧いただくときの注意事項 | 週間高世帯視聴率番組10
- 首都圏ラジオ聴取データ × radikoデータ~推計によるラジオ聴取データの365日化へ~ | ニュース || コーポレートサイト
- 週間高世帯視聴率番組10
- 2018年ドラマ視聴率ランキング | ドラマ投票所
- radiko(ラジコ) | ラジオがインターネット(アプリやパソコン)で無料で聴ける
【統計 小ネタ】チャーノフの顔グラフ
先日、統計検定の準1級を受けてきました。
結果の良し悪しは別として、勉強するなかで面白い話をいくつか拾ったので少しずつ紹介していきます。
今回はチャーノフの顔グラフについて
データをグラフ化する方法はいくつかあります。よく使われるのが棒グラフや折れ線グラフ、散布図などです。 ただ、面白いことを考える偉人もいたようで、データを顔の絵にすることで違いがわかりやすいのではないかと。
なるほど??
チャーノフの顔グラフ 概要
チャーノフの顔グラフは、Herman Chernoffさんが発表したデータの可視化の方法。恐らく発表論文は これ http://The use of faces to represent points in k-dimensional space graphically (中身は読んでません)。Wikipediaのこの方のページによるとまだご存命のよう。
人間は表情のちょっとした変化に敏感なので、データの可視化に表情を使えば良いのではという発想のよう。なるほど、ちょっと笑っただけでも人間すぐにバレてしまうしアイデアには納得。
論文としては、データ(数値)を顔の絵にするための方法も楕円とかを組み合わせるルールを定義している。(そうしないと客観評価もできないから当然か。) このときは最大18次元のデータを扱えるようにしたらしい。 世の中の実装はそのルールに必ずしも従っていないようだが、概要は同じ。
試してみる
顔グラフの絵は検索すればたくさん出てくるが、使ってみてどうなのかを知りたかったのでデータを作って試した。 なお、顔グラフ表現の実装は下記のものを使わせて頂いた。 aoki2.si.gunma-u.ac.jp
架空の学校での生徒のテスト結果を考える。表が生データ、顔の絵がそれぞれに対応するグラフ(国~社を1~5次元目に割り当て)だ。


どうだろうか。
比較用にレーダーチャートも作成した。こちらは下記記事の実装を使わせて頂いた。

感想
まぁ確かに顔グラフではそれぞれ違うのは分かる。
一方で、何がどのくらい違うのかはさっぱりだ…
レーダーチャートは数値で示されるし、今回の場合はチャート内の面積も「全体的な成績」として意味を持つので、顔グラフより見やすくて情報も多く優れているという感想だ。
10次元くらいになるとレーダーチャートでは見るのも大変になるので、その時に顔グラフの出番になる…だろうか。今どきなら3Dモデルでリアルな顔をグラフとして使うこともできるだろうから、もしかしたら今後機会がある、かもしれない。
参考, 利用
- 書籍 「人文・社会科学の統計学」東京大学教養学部統計学教室 編(出版社サイト)
- https://amstat.tandfonline.com/doi/abs/10.1080/01621459.1973.10482434#.XQ9134_gqHs
- Python による統計処理
- Chernoff Faces in Python with Matplotlib · GitHub
- Chernoff face - Wikipedia
- Herman Chernoff - Wikipedia
- Matplotlibでレーダーチャートを描く(16行) - Qiita
- pip install して import するだけで matplotlib を日本語表示対応させる - Qiita
3段階 Kaggle環境構築
先月よりKaggleに挑戦し始めました。 コンペに参加しながら計算環境について検討したので、これから始める方向けにまとめます。 環境構築に時間を掛けずに、アルゴリズムの検討に時間を掛けたいですね。
想定読者
- これからkaggleに挑戦する、もしくは挑戦し始めたくらいで計算環境が未整備
- WindowsコマンドプロンプトやLinuxターミナル(Bashなど)のコマンド実行方法がわかる
- コマンドを覚えている必要はない
- Windowsユーザー
- KaggleではPythonを使って挑戦する
- Pythonの使用経験は多少ある
この記事に書くこと/書かないこと
書くこと
- Kaggleに挑戦するにあたってオススメの計算環境,ツール
書かないこと
- Kaggleで使うべきアルゴリズム
- Kaggleの公式サイトの見方(有用な議論の発見の仕方など)
各環境の利用目的/導入方法概要
ローカルでの動作環境構築 → Google Colaboratoryの利用 → GCP(GCE: Google Compute Engine)上で環境構築の順でステップアップしながら整えていくのが良いと考えている。 それぞれの利用目的と導入方法の概要をまとめると次の通り。
※補足:Kaggle Kernelは、Commit時に再実行されたり、出力したファイルをCommitせずにローカルに持ってくる手軽な方法がなかったりして、ちょっと使いやすさで他に劣ると考えているためここでは紹介しない。
1. ローカル
利用目的
- Kaggle参加にあたって使うツール類やSubmitまでの手順に慣れる
- 軽い処理を気軽に試す
- 電気代だけで何時間でも動かせる環境として使う
導入方法
- Pythonディストリビューションを導入する
- AnacondaかWinPython
2. Google Colaboratory
利用目的
- ネットワーク越しの環境に慣れる(セッションがいつ切れても良いように実装する)
- GPU/TPUを使って計算する
導入方法
- ノートブックファイル,データを全てGoogle Driveに保存する
- Google ColaboratoryのGoogle Driveアクセス機能を使う
3. GCP(GCE: Google Compute Engine)
利用目的
- 処理時間(待ち時間)を短縮する
- 大量メモリを必要とする処理を行う
導入方法
構築方法
1. ローカル(Windows)
Windowsで機械学習用途でPythonを使うには、Pythonディストリビューション(便利ツールやライブラリがセットになったもの)を導入するのが圧倒的に楽である。
一番の有名どころはAnacondaだが、自分はWinPythonを使っている。
Anaconda
WinPython
Kaggleでよく使われるライブラリのうち、AnacondaやWinPythonに含まれないものは追加でインストールする。
WinPythonではXGBoostとLightGBMが含まれていなかったので追加する。
'WinPython Command Prompt.exe'を起動すると各コマンド(pythonやpipなど)にPATHが通った状態でコマンドプロンプトが起動するので便利。
コマンドプロンプトが開いたら、次のようにするだけでインストールできる。
pip install xgboost pip install lightgbm
ここまででツールは揃った。
コーディングのエディタなどはそれぞれ好みがあると思うが、KaggleではJupyter notebookやその類似のものを使うことが多い。(Kaggleが提供しているKernelというツールや、後述するGoogle Colaboratoryもその一種。)Jupyter Notebookではグラフや文字列の出力をそのまま保存できるのでとても便利。
Web開発ではVisual Studio CodeやPyCharmを使うことが多いと思う。それらにもJupyter Notebook統合の機能があり、特にPyCharmのコード補完機能は優れている。が、自分はいまいち使いにくいと感じたので素のJupyter Notebookを使っている。
'Jupyter Notebook.exe'を起動すると勝手にブラウザが開いてJupyter Notebookが使える。
Jupyrter自体の使い方は検索するとたくさん出てくるので他に任せる。セルの実行と追加/削除のショートカットキーは覚えているかどうかで効率がかなり変わると思う。
2. Google Colaboratory
ローカル環境で動かすことに慣れたら、Google Colaboratory(以下Colab)で動かすことに慣れるようにする。 ColabはGoogleが提供するサービスでJupyter Notebookに似た操作感がある。(ただしショートカットキーが異なる。)
Colab使う際には、Google Drive(以下Drive)に.ipynbファイルを保存するのが一般的。また、Kaggleで使うデータもDriveに置くのが簡単。
Colabの画面から直接ファイルを新規作成したりファイルアップロードしたりもできるが、既定の場所に自動でファイルが作られてしまう。そのため、先にDriveにファイルを作っておいて、それを編集したほうがファイルが迷子にならずに済む。
まずはDrive上でそれっぽくフォルダを作る。(input,output,scriptフォルダを作るのが一般的のよう。)
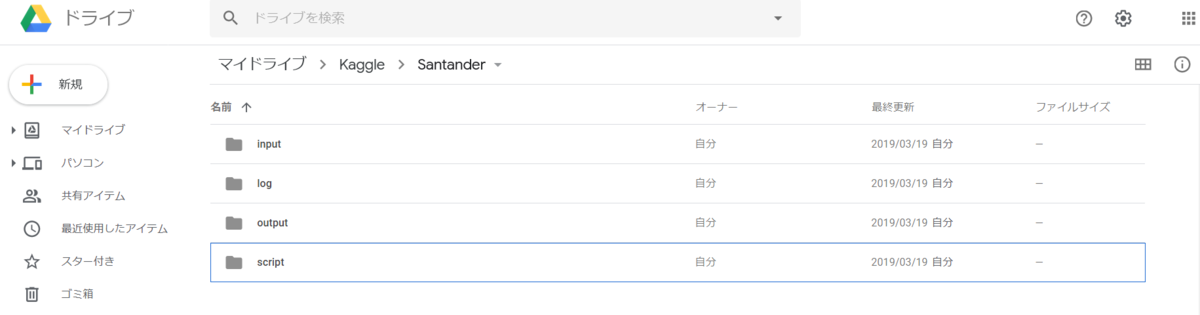
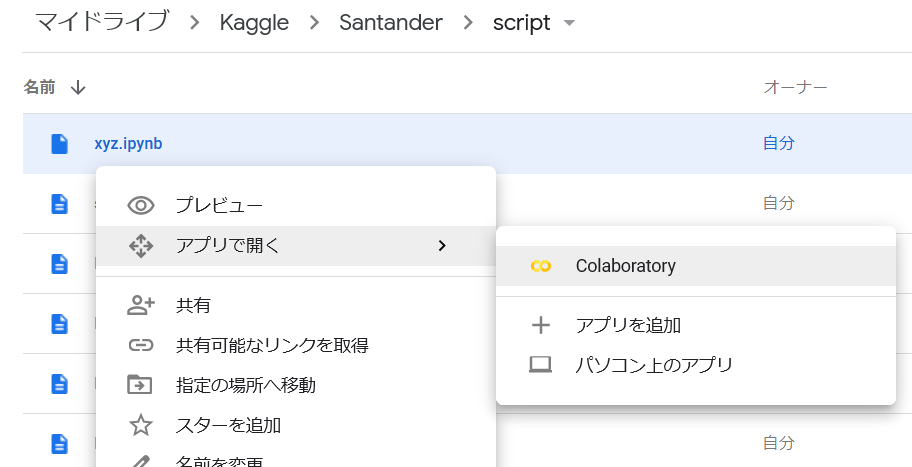
ローカルのJupyter Notebookファイル(.ipynb)をDriveにアップロードしたら、右クリックメニューで「アプリで開く」→「Colaboratory」の順に選ぶと、Colabでそのファイルを開くことができる。 コピーではなくファイルそのものが開かれるので、編集結果は何もせずともそのまま反映される。
Colabの使い方はローカル環境で動かすJupyter Notebookと似ているが、クラウドで動いている点と、一定時間で接続が切れてしまう点が異なる。そのため、テストデータや出力結果の保存をどうするかが問題になる。
Colab上では、Driveとの連携のための特別パッケージを使うことができ、Driveのファイルの読み書きをスムーズに行うことができる。参考:ColaboratoryでのGoogle Driveへのマウントが簡単になっていたお話
私はいつも最初にDriveのマウントとカレントディレクトリの変更を実行している。 URLが表示されるのでそちらにアクセスするとGoogleアカウントとの連携画面に移動する。表示された通りに進めればOK。
# 自分のGoogle Driveにアクセスできるようにする # Google Driveのトップが "/content/drive/My Drive/"になる from google.colab import drive drive.mount('/content/drive') # 自分は"Kaggle/Santander/script"にノートブックファイルを配置しているので # 相対パスで扱いやすいようにos.chdir()でカレントディレクトリを変更する os.chdir("/content/drive/My Drive/Kaggle/Santander/script")
GPUやTPUが必要になったら、「ランタイムの切り替え」をすると使えるようになる。
ただし、Kaggle初心者がGPUやTPUの必要になる画像/音声データを使ったコンペに参加するのは、トライ・アンド・エラー回数が少なくなるので敷居が高めだと思う。
3. GCP(GCE: Google Compute Engine)
自分のようにノートPCしか無い人はデータとアルゴリズムによっては足りなくなる。Google Colabも12GBくらい使えるが、それ以上はエラーになってしまう。また、処理時間が掛かってしまい待ち時間が長くなってしまうケースというのがありうる。
そんな時にはクラウドサービス上で自分用のサーバーを建てて、その中でJupyter Notebookを動かすとよい。 特にGoogle Cloud PlatformのGoogle Compute Engineがオススメだ。 また、Kaggleが提供しているDockerコンテナが存在するので、それを使う方針で説明する。
GCEの選定理由
最初に悩むのが、どのクラウドサービスを使うかだと思う。クラウドサービスとして個人用で候補に上がるのはAWS EC2, MS Azure VM, GCPのGCEあたりだろう。Kaggle用としてはGCEを使うのがおすすめなので、手順としてはそれを前提とする。
GCEをおすすめする理由は、環境構築の手軽さとお金事情だ。
Microsoft AzureのVirtual Machine
GCE上の環境構築
まずはGCEのインスタンス(マシン)を用意する。
詳細手順は他の記事参考:GCP(Google Cloud Platform)での無料GCE(Google Compute Engine)インスタンス作成に任せるとして、ポイントは下記の通り。
- リージョンは料金表を見ながら安いところにする
- 自分はus-east1にしている
- CPU,メモリは後から変更できるので、ひとまず安いもので十分
- ディスクは30GB以上欲しい
- データを一時的に置いたりするため
- HDDで十分速い
- あまり大きな容量にすると停止中もお金がかかるので注意
- OSはUbuntuが何かと情報が多くて無難
- プリエンプティブのオン/オフのメニューは隠れているので探す
また、自分の場合は普通のインスタンスとプリエンプティブのインスタンスを1つずつ建てている。多くの人が使っているためか、プリエンプティブインスタンスが使えない事があったため。そのような状況を1週間で2回経験している。
GCEのインスタンスを作成すると自動で起動する。停止や再起動はブラウザから行える。
起動中のインスタンスにアクセスして環境を整えたりするのには、Cloud SDKを使うのがよい。Googleアカウントでログインすると、暗号化通信のためのあれこれを勝手にやってくれる。インストーラをダウンロードしてきて指示の通りに進める。
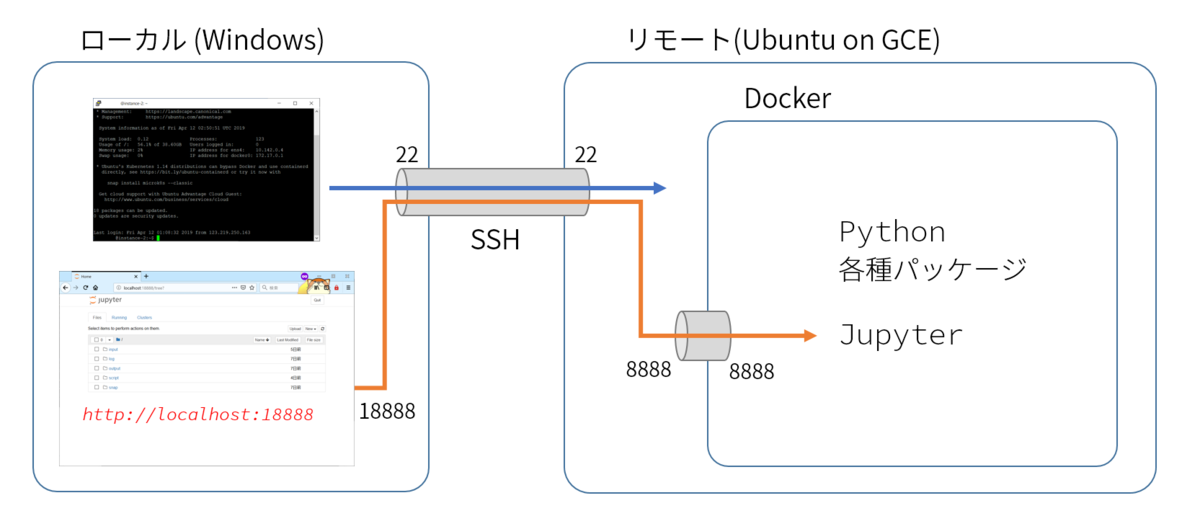
Cloud CLIがインストールできたら、コマンドプロンプトで起動しているGCEインスタンスにアクセスする。
このとき、今後のJupyterのアクセスのために毎回 "-- -L 18888:localhost:8888" とオプションをつけるようにする。
(あとで説明する。)
gcloud compute ssh {インスタンス名} --zone {ゾーン名} -- -L {ローカル側ポート番号}:localhost:{リモートのポート番号} # 例) gcloud compute ssh instance-1 --zone us-east1-b -- -L 18888:localhost:8888
Dockerインストール
GCEで建てたマシンに地道に準に必要なものをインストールしたり、ローカル環境と同様にAnacondaを使っても良い。
しかし、LinuxマシンならDockerを使うのが便利。Kaggleが公式に提供しているDockerイメージを利用でき、Kaggle Kernelと同じライブラリが使えるようになる。個人的にKernelの操作性は微妙だと思っているが、ライブラリ類は揃っているしKernelコンペというものもあるので、同じ環境が揃うのは嬉しい。
※ ただしGPU利用版は未提供
Docker公式サイトに各ディストリビューションでのインストール方法が載っているのでその通りに実行していく。
日本語で読みたい場合は参考:Ubuntuにdockerをインストールする の「2. リポジトリからのインストール」「4. 一般ユーザでの実行」を実行して、一旦接続を切ってgcloud comute ssh {インスタンス名} --zone {ゾーン名} -- -L {ローカル側ポート番号}:localhost:{リモートのポート番号}で接続しなおす(マシンの再起動は不要)。
Docker起動
次のコマンドでKaggle公式のDokerを起動する。
docker run --name kaggle -v $PWD:/tmp/working -w=/tmp/working -p 8888:8888 -itd kaggle/python jupyter notebook --no-browser --ip="0.0.0.0" --notebook-dir=/tmp/working --allow-root
オプションが長いので説明。爆速でKaggle環境を構築するに記載の手順ほぼそのままだが、デーモン起動する方が便利なのでその点を変えている。
--name kaggle- kaggleという名前で起動する
docker stop kaggleとすれば止まる、docker start kaggleとすれば再び起動する
- kaggleという名前で起動する
-v $PWD:/tmp/working -w=/tmp/working- dockerの中と外とでカレントディレクトリを共有する
- dockerを停止してもファイルが残るようになる
-p 8888:8888- ポート8888番を8888番に転送する
-itd kaggle/python jupyter notebook --no-browser --ip="0.0.0.0" --notebook-dir=/tmp/working --allow-root
無事に起動しても何らかのエラーが出ても、コンソール上には何も表示されない。docker logs {コンテナ名}コマンドで出力を確認し、http://{12桁の英数字}:8888/?token={長い英数字}と表示されたら問題なくJupyterが起動している。
docker logs kaggle
# 出力例 [I 01:20:01.337 NotebookApp] The Jupyter Notebook is running at: [I 01:20:01.337 NotebookApp] http://3078d3d264c3:8888/?token=c7601ca8dd41f61e739373168c07bb232557a5de8a19357b [I 01:20:01.337 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation). [C 01:20:01.338 NotebookApp] Copy/paste this URL into your browser when you connect for the first time, to login with a token: http://3078d3d264c3:8888/?token=c7601ca8dd41f61e739373168c07bb232557a5de8a19357b&token=c7601ca8dd41f61e739373168c07bb232557a5de8a19357b
Jupyterに接続
上の手順でhttp://{12桁の英数字}:8888/?token={長い英数字}が無事に表示されたら、ローカル端末からGCEの上で動くJupyter Notebookにアクセスする。
表示されたURLの{12桁の数字}の部分をlocalhostに、ポート番号8888を18888に変えたものをブラウザに打ち込む。http://localhost:18888/?token={長い英数字}
自分はPuttyでのクリップボードへのコピー方法が最初分からなかったが、該当部分をマウスで選択するだけでいい。(ctrl-cは別の意味になるので)。
Jupyter Notebookの画面が開かれればOK!存分にKaggleを楽しめる。
なお、gcloudコマンドで起動したコンソール画面(Puttyの画面)は閉じないこと。理由は下の補足参照。
うまくいかない場合は、
docker logs kaggleでエラーが表示されていないか- ここまでの手順で
8888と18888を間違っていないか gcloud compute sshで開いた黒い画面を閉じていないか- (docker logsにエラーもアクセス履歴も何もないなら)
gcloud sshのときに-- -L 18888:localhost:8888を忘れていないか
を確認する。
GCEのシャットダウン、再起動
無駄な課金を防ぐには、使わない時にはGCEのインスタンスをシャットダウンしておく必要がある。 (GCEではOSシャットダウン時はディスクのみ課金、サービスによって扱いが異なるので注意。)
ブラウザから強制的に止めてしまっても自分の環境では問題は起きていない。気になる人は念の為に次のコマンドで停止する。
docker stop kaggle # "kaggle"という名前のDockerコンテナの停止 = Jupyterが止まる sudo shutdown -h now # サーバーのシャットダウン
逆に停めていたサーバーを起動するときには、ブラウザから操作すればよい。
サーバーを起動するだけでは中のDockerコンテナまでは起動しないので明示的にコマンドで起動する。
毎回docker runするのではなく、2回目以降はdocker startする。
docker start kaggle # "kaggle"という名前のDockerコンテナの起動 # この後、docker logs kaggle でアクセスURL(token)を確認する
Google Cloudのスマホアプリからもステータスチェックや開始/停止できる。停止漏れの確認に使える。
データの保存先
軽いファイルの保存や出力結果をローカルで軽く確認したいときは、Jupyter Notebookのダウンロード機能、アップロード機能を使えばいい。
大きなファイルサイズのものはGoogle Cloud Storageにデータを保存しておくのがよい。アメリカに置けば5GBまで無料らしい。
GCEのマシンにはデフォルトでgsutilというGoogle Cloud Storageを操作するためのツールがインストールされている。
ブラウザで操作しても良いが、大きなファイルサイズのデータは、これを使ってGoogle Cloud Storageとやりとりをすると非常に高速。詳細は他記事を参照。
スペック変更
マシンをシャットダウンしている間なら、CPUとメモリの量を変更できる。 データサイズとアルゴリズムによって必要なメモリは異なるので、動かしながら調整していくといい。
もともとGCEでは一度マシンを削除しないと変更できなかったらしくその時の情報が検索すると出てくる。しかし今はブラウザからクリックだけでできる。(スクリーンショットは載せてもすぐに変わりそうのため省略する)
補足1:gcloudコマンドのオプションとポートの関係
gcloudに接続するときのコマンドは下記の通り(再掲)
gcloud compute ssh {インスタンス名} --zone {ゾーン名} -- -L {ローカル側ポート番号}:localhost:{リモートのポート番号} # 例) gcloud compute ssh instance-1 --zone us-east1-b -- -L 18888:localhost:8888
この--から後が、SSHポートフォワーディングの設定になっている。
上記の例ではlocalhost:18888にアクセスするとSSHのトンネルを通って(つまり暗号化された状態で)サーバーの8888番ポートにアクセスしたことになる。(サーバー上でlocalhost:8888にアクセスしたのと同じになる。)
さらに、Docker起動時に-p 8888:8888指定をしているので、Ubuntuの8888ポートがDockerコンテナの8888ポートに繋がる。
この仕組みを利用してローカルのブラウザからJupyterにアクセスしている。そのため、GCEのネットワーク設定を変えることなくJupyterにアクセスできるようになる。
ポートフォワーディングはPuttyの画面を開いている間だけ有効なので、Puttyの画面を閉じてしまうとブラウザからアクセスすることができなくなるので注意。
補足2:ネットワークファイアウォールの追加設定
補足1の通り、SSHポートフォワーディングを利用してサーバー(の中のDockerの)Jupyterにアクセスしている。そのためSSH用の22番ポートだけ使えれば良い。
GCEではデフォルトで外部からの8888番に対するアクセスは拒否されているが、内部からのアクセスは許容するdefault-allow-internalというルールが付いている。
外部アクセス禁止かつJupyterの起動時にtokenを使っていれば、すぐさまセキュリティ上問題になる可能性は低いと思う。一方でroot権限で動いているJupyterからはどんな事でも出来てしまうので、万一不正アクセスされた場合には怖い。
そのため、GCEの「VPCネットワーク」→「ファイアウォールルール」で、内部外部を問わず8888ポートへのアクセスを禁止しておくことを推奨する。
補足3:JupyterのPassword認証を使いたい / 起動ごとにtokenを調べるのが面倒 なとき
Jupyter Notebookの設定変更はjupyter_notebook_config.pyファイルを書き換える方法が一般的だが、実は起動オプションだけで相当数の(一時的な)設定変更ができる。
参考:Jupyter Notebook公式
例えばtokenは使わず毎回同じパスワードで起動したいとする。
パスワードの生成方法はJupyterを導入しよう -リモート編-などを参考にして、下記オプションで起動すればjupyter_notebook_config.pyを変えることなく設定を反映させて起動できる。
# passwd()して"ubuntu"を変換したら'sha1:a0a28df801c9:7bab5ea21d39cf03bb54100dcaf8cf9664dc9ddb'になったとする --NotebookApp.token='' --NotebookApp.password='sha1:a0a28df801c9:7bab5ea21d39cf03bb54100dcaf8cf9664dc9ddb'
ただし、セキュリティとしては弱くなる。 補足2に書いた通り、万が一乗っ取られると危ない。補足2のファイアウォールルールの追加はセットで行うべきと思う。
まとめ
3段階でKaggleに挑戦するための環境を整えていく方法を紹介した。
それぞれに利点/欠点があるので、コンペの期限やお財布事情(無料トライアル枠の残高)などを見ながら使い分けていきたい。
この記事で記載できなかったこと
- GCP上でGPUを計算に使う環境の構築
- 現状ではCPU対応のDockerイメージしか公開されていない
- GCEのCUDAドライバ対応マシンイメージを使う + tensorflowなどをインストールし直す といった手順が必要なはずだが試せていない
- Dockerを使わずにGCP上で手軽に環境を整える方法
- 本来は何度もマシンの作成/削除を繰り返さないならDockerを使う必要はない
その他
本文中で紹介しなかった参考記事/動画
Coursera Introduction to Deep Learningコースの受講感想
Introduction to Deep Learningコースをほぼ修了したので感想です。
「ほぼ修了」と書いたのは、レビュー結果待ち状態のものがあるからです。あと自分が他の人のレビューもしないといけないのですが、まぁ大体終わったということで。
以前、Stanford大学のMachine Learningコースを受講しました。
Coursera Machine Learningコースの受講感想 - わくわくとオーボエ
この講義はその続きではないのですが、自分の場合は続きとして受けても問題なさそうだと判断してこれを選んでいます。
長くなったのでまとめから
- 扱いは「上級」だがあくまで「Introduction」の範囲
- ITエンジニア向けの初級から中級本くらいの内容
- 複数講師なので、テーマごとに聞きやすさが違う(教師なし学習は聞きにくい)
- 50時間くらいかかった
- 演習問題を解きたい & 英語学習を兼ねられる にメリットを感じるなら受けても良い
- 難易度、時間、費用的には、日本の書籍で十分学習できる範囲
- 次コースの"How to Win a Data Science Competition: Learn from Top Kagglers"に必要かと思い受けたが怪しい気がしている
- 実際どうだったかは受けてから書く
コース情報
主催、講師
ロシアのNational Research University Higher School of Economics(国立研究大学高等経済学院)が主催している講座。 Advanced Machine Learningという専門講座に含まれる最初のコース。
先生は4名。分野ごとにバトンタッチ。
カリキュラム
全部で6週を想定したオンライン講義で、示されている所要時間を合計すると約38時間です。
おおよその内容は次の通り。
- Week 1: Introduction to optimization
- 線形モデル
- 正則化
- 確率的な最適化手法
- Week 2: Introduction to neural networks
- 多層パーセプトロン
- 行列の微分計算
- TensorflowとKeras
- (honor) ニューラルネットワークの自前実装
- Week 3: Deep learning for images
- CNNの考え方(畳み込み、プーリング)
- 学習のための工夫
- 有名なCNNアーキテクチャと学習済みモデルの再利用方法
- コンピュータービジョンにおけるCNN活用例
- Week 4: Unsupervised representation learning
- Week 5: Deep learning for sequences
- RNNが生まれた経緯と考え方
- RNNの学習の難しさ
- 単純RNNの課題と有名なRNNアーキテクチャ
- RNNの活用例
- Week 6: 総合演習
- CNN + RNN(conditional sequence generation)
難易度は「上級」。
また受講の前提知識として以下が記述されています
その他
残念ながら字幕に日本語はありません(2019年2月末時点)
英語字幕はかなりよく出来ています(後述の通り教師なし学習の部分を除く)
学習実績
時間
このコースの学習の途中から、アプリで学習時間の実績をつけるようにしました。
途中からだったのとタイマーをつけるのを忘れたりしたせいではっきりしないのですが、オプション課題を除いて50時間くらいで最終課題の完成まで行けたと思います。コース想定が38時間(オプション課題込み)なので、だいぶ掛かってしまったと思う。
時間の掛かった理由は2つ。ノートをとる時間と、英語の発音です。
ノートをとる時間
前回受けた講義(Stanford大学 Machine Learning)では、講義スライド(講師の書き込みあり)がPDFでダウンロードできたほか、講義内容をまとめ直したものも閲覧できます。また、もともと無料講義なので必要になったら受け直すことも自由にできるものです。
一方でこのIntroduction to Deep Learningコースでは、ダウンロード資料などは用意されていません。さらに有料講座で月ごとに課金のため、ずっと講座を聴けるようにしておくのも現実的ではなく。 そのため、各講義動画ごとに内容を自分で残しておかないと、何の話をしていたかも分からなくなってしまいます。
ノートは話の内容が分かっていれば書くのは大変ではない…かと思いきや、意外と大変です。というのも、英語から日本語へ翻訳するコストが自然に掛かってしまうためです。(英語のままメモに残せば書くコストは減りますが読むコストが上がります。) 講義スライドは分かりやすいものの情報量が少なめなので、スライドのスクリーンショットを手元に残すだけでは足りないかと思います。
英語の発音
英語の講義なので、発音の分かりやすさと字幕の精度には慎重になってコースを選択したつもりでした。(事前に複数本の動画をお試し視聴した) ただ、講師が4人もいるとは思わず。。
4人のうち、教師なし学習を担当している方の話す速度と発音がちょっと…。字幕も間違っていたり[INAUDIBLE]となっていたりが目立ちました。 そのため、自分の能力では5分の視聴に1時間近く掛けるペースになりました。
他の3人の講師については聞き取りやすい発音です。その中でも特にCNNの担当の講師がゆっくりはっきり綺麗な発音でした。
内容理解
上に書いたとおり、教師なし学習については英語理解がむずかしく、ぼんやりした理解度です。それ以外はちゃんと動画を見て分からない部分はネットで少し検索したりすれば、問題なく理解できました。
感想
内容の広さ,深さ
書籍「ゼロから作るディープラーニング」は手元にあったので適宜参照しながら進めました。このコースの方がやや詳しめ(深め)ですが、コースのCNNまでの内容がおおよそこの本の内容をキュっとまとめた感じでしょうか。コースとしてはTensorflow/Kerasを使って実装することに主眼が置かれているものの、途中のオプション課題でNumpyのみでニューラルネットワークを作るというのがあり、近しいものを感じます。
教師なし学習とRNNについては、書籍を持っていないので目次を見る限りではありますが「ゼロから作るディープラーニング2」と7割くらい重なっていそうです。書籍にあるAttentionというものは、「このコースでは触れない」と途中の動画で言っていました。(Advanced Deep Learningの残りの6コースの中で扱うそうです。)
"Introduction to Deep Learning"というタイトルからするに浅く広くの学習を目指しているのでしょう。この分野の全容を知るわけではありませんが、おおよそ名前通りのコースだと感じます。
難易度「上級」について
このコースだけではなく、7コース合わせて「上級」表示がされているような気がします。上述の通り、ゼロから作る~という書籍とレベル感として近いです。基礎の部分が省略されたのを踏まえて、中級くらいじゃないでしょうか。
ただ、この内容の後に6コース、総計216時間の講座が後ろに控えていると思うと、それらの後半は間違いなく「上級」でしょう。
演習
環境構築のハードルの低さ:◎
コース用のGitHubリポジトリがあり、そこを参照すると演習に必要なライブラリとバージョン、それからGoogle Colabを使う時に追加で必要な補助記述などが書かれています。ローカルで作業する人向けに、Anacondaの導入方法も。 ここに書いてあるとおりにColabを利用すれば(少なくとも今の時点では)何も問題なく作業を進めることができました。Tensorflowのバージョンが新しくなった時にWeek 2の課題を更新しているらしく、そういった点でも安心して演習に取り組めます。
内容:△、方式:○
演習は全体に穴埋め方式です。全体の流れは実装されていて、1行から10行程度までの穴埋めが多数ありコメントで方針が示されています。 これはもう少し全体に生徒の記述量を増やしても良いかなと思いました。
新たに解きたい問題があったとして、全部自力(もちろんKerasなどは使う)で組めるようになったかというと、怪しいです。ただ、今回のコードをベースに実装すれば良いと思うので、ちゃんと考えながら読んだという点では意味はあると思いました。
オプション課題と最終課題の2回、ペアレビューとして他の人のソースコードを読む機会があります。Pythonは書き方がばらつきにくいと言われていますが、それでも色々書き方は出てきます。また、動作確認用に組んだネットワークにも個人差が出てきます。いくつもの結果、ちょっと失敗例に近いようなものも含めて見ることが出来るのは参考になりました。 講師が違うからか、それぞれ課題側にも個人差があってそれも同様です。
ミニクイズ
講義動画の途中で、四択のミニクイズが出されます。このコースでは解説したことをクイズに出すのではなく、クイズに出したことを解説する順になっています。これが意外と理解の助けになりました。
誰にオススメするか?
選ぶとしたら、「締め切りと演習問題があったほうが学習に取り組みやすい」かつ「英語の勉強も兼ねたらラッキーくらいに思う」人でしょうか。
入門者ではなく、理論を突き進めたい人でもなく。あくまでIntroductionの範疇かつ普通のペースでやったら修了までに時間もお金もかかるので、それでいて巷に溢れる良書を退けてこのコースを勧めたくなる人は絞られると思います。
自分の場合は次の"How to Win a Data Science Competition: Learn from Top Kagglers"に期待をしていて、その前段として受けたという側面が強いです。ただ、KaggleでDeep Learningが主流かというとそうではないのではと気づき。有用だったかどうかは、そちらを修了する頃にまとめたいと思います。